|
|
 |
|
|
|
Wolfgang Marks: Die Formatierte DNA
|
|
|
Architekturproteine.
Versuch einer neuen Ordnung.
Da die Identifizierung von Genen, die zu einer Genfamilie geh√∂ren, selbst mit IMPACD® noch viel Zeit kostet, habe ich (auch aus patentrechtlichen Gr√ºnden) nicht f√ºr alle Familien die bereits bekannten Proteine und Gene durch Gene und Proteine erg√§nzt, die nach meiner Ansicht in diese Gruppe geh√∂ren, sondern lediglich f√ºr die HMGN-Familie eine komplette, systematische, auf Nukleosomengr√∂ssen bzw. Formatierungshormonen beruhende √úbersicht und Ordnung erstellt.
Der SAF-A/B-Familie habe ich - ebenso wie der SATB-, der HMGA- und der HMGB-Familie – einige bereits bekannte Proteine zugeordnet und diese Proteine zum Teil mit einem bestimmten Hormon verknüpft, um aufzuzeigen, wie sich die oben skizzierte Systematik auf diese Proteinfamilien übertragen lässt.
Im Anschluss an die so erstellten Tabellen habe ich bereits Gewusstes zu den einzelnen Proteinfamilien zusammengetragen. Da das Material zu allen genannten Proteinen überaus umfangreich ist, kann das hier Gesagte nur ein komprimierter abstract sein. Wer sich weiter informieren will, findet zu allen Proteinen im Internet und in der Primär- sowie Sekundärliteratur zahlreiche Quellen.
Bei der folgenden zusammenfassenden Darstellung der SAF- und SATB-Protein-Familien stütze ich mich auf Aussagen in der Dissertation von Sandra Götze170. Die sich daran anschliessenden Feststellungen zu den drei HMG-Proteingruppen basieren im Wesentlichen auf Arbeiten der Arbeitsgruppe um Robert Hock an der Maximilians-Universität Würzburg und einer Dissertation171 von Ulrich Körner aus eben dieser Arbeitsgruppe.
|
|
|
|
SAF-Family:
Nr. of Proteins: 30
Expressed from – to: day 110 - adult
Correl. Group of Hormones: Prim. Transcript. Hormone (FH 12-19)
Organis. of Hormonal System: 3-steps
|
|
|
|
Protein-Ident.
|
Actual Name
|
Primary Transcr.-Hormone
|
FH
|
|
|
NP_114032.2
|
HNRNPU-a (SAF-A)
|
ACTH
|
CRH
|
|
|
NP_004492.2
|
HNRNPU-b
|
Adrenalin
|
CRH
|
|
|
NP_002958.2
|
SAF-B
|
?
|
GH-RH
|
|
|
Die SAF- Protein-Familie.
Die von der Gruppe Fackelmayer bis dato entdeckten und charakterisierten SAF-Proteine SAF-A und SAF-B (SAF= Scaffold Attachment Factor) binden spezifisch an bestimmte SMARs und haben nach Meinung der Gruppe Einfluß auf wichtige genetische Prozesse wie DNA-Replikation und Genexpression. Dafür sei eine Wechselwirkung mit anderen Proteinen des Zellkerns, mit DNA und vermutlich auch mit RNA notwendig. Neueste Ergebnisse aus dem Labor Fackelmayer lassen erkennen, daß diese Wechselwirkung zumindest bei SAF-A von einer speziellen posttranslationalen Modifikation des Proteins reguliert wird, der asymmetrischen Methylierung von Arginin-Seitenketten. Diese Modifikation ist auch von zahlreichen anderen nukleinsäurebindenden Proteinen des Zellkerns bekannt, ihre funktionelle und strukturelle Rolle ist bis heute jedoch ungeklärt.
SAF-A, das auch unter dem Namen SP120 (Tsutsui 1998) oder hnRNP-U bekannt ist (Göhring und Fackelmayer 1997), kann wie SAF-B neben RNA auch DNA binden. Beide Proteine gehören zu einer Gruppe ubiquitär exprimierter Proteine, den sogenannten hnRNPs (heterogeneous nuclear ribonucleoproteins), die Komplexe mit hnRNA (Primärtranskripten) bilden sollen und offensichtlich mit der Bildung von hnRNAs und messenger-RNAs korreliert sind.
Die Primärstruktur des Proteins spiegelt seine duale Funktion bei der Organisation des Chromatins wieder: während eine C-terminale RGG-Box die Bindung von RNA und Einzelstrang-DNA vermittelt, ist die N-terminale 45 Aminosäuren zählende SAF-Box für die Bindung an SMARs verantwortlich.
Das SAF-A Protein hat eine starke Tendenz zu polymerisieren und kann als Multimer an SMAR-Elemente über einen Prozess binden, der als mass-binding bezeichnet wird. SAF-A Proteine zeigen eine erhöhte Polymerisationsbereitschaft, wenn sie an SMAR-Elemente gebunden sind. Mehrere SAF-Boxen können dann eine starke DNA-Protein Interaktion vermitteln (Kipp et al. 2000).
Die SAF-SMAR-Bindung soll über die kleine Furche der DNA vermittelt werden – sie soll optimal sein, wenn sogenannte AT-Patches in bestimmten Abständen in der DNA angeordnet sind (Tsutsui 1998).172 Vergleicht man qualitativ und quantitativ die Bindung von SMAR-Elementen an SAF-Boxen, die über Sephadex-Säulen immobilisiert wurden, mit der DNA-Bindung an eine isolierte Kernmatrix, lässt das den Schluss zu, dass ein Großteil der DNA/Kernmatrix-Interaktionen über SAF-Proteine vermittelt wird. Dass SAF-Proteine essentiell für eine geordnete Zellkernstruktur sind, sieht man auch am Beispiel einer N-terminalen SAF-A Mutante, der die SAF-Box fehlt. Transfiziert man die deletierten Proteine transient in COS7-Zellen, kommt es zu einer signifikanten Abnahme der Zellproliferation (Kipp et al. 2000).
Die SATB-Protein-Familie.
Über SATB-Proteine habe ich in Teil II im Zusamenhang mit der Stillegung von Genen und Chromatin-Domänen schon referiert. Die untenstehende Tabelle ist ein Versuch, sowohl bereits bekannte als auch vom Autor postulierte SATB-Proteine in einen systematischen Zusammenhang zu bringen.
|
|
|
|
SATB-Family:
Proteins: 30
Expressed from: day 80
Correl. Group of Hormones: Prim. ARBP-Group:
Proteins: 52
Expressed from: day 110
Correl. Group of Hormones: Secondary Transcriptional Hormones (FH 12-19)
Organis. of Hormon. System: 3-steps
scriptional Hormones
Organisation of Hormonal System: 2-steps; 3-steps
|
|
|
|
Protein Ident
|
Act. Name
|
Formatt. Hormone
|
|
|
|
NP_001124482
|
SATB1
|
Thymosin-10
|
|
|
|
putativ/w.marks
|
SATB2-?
|
Thymosin-ß15
|
|
|
|
NP_056080
|
SATB2
|
CRH
|
|
|
|
ENSP00000260926
|
SATB2-201
|
Gn-RH
|
|
|
|
NP_004822
|
MED26173
|
MSH-RH
|
|
|
|
putativ/w.marks
|
SATB2-?
|
Leuzin-Enkephalin
|
|
|
|
ENSP00000333367
|
SATB1-201
|
Leuzin-Enkephalin
|
|
|
|
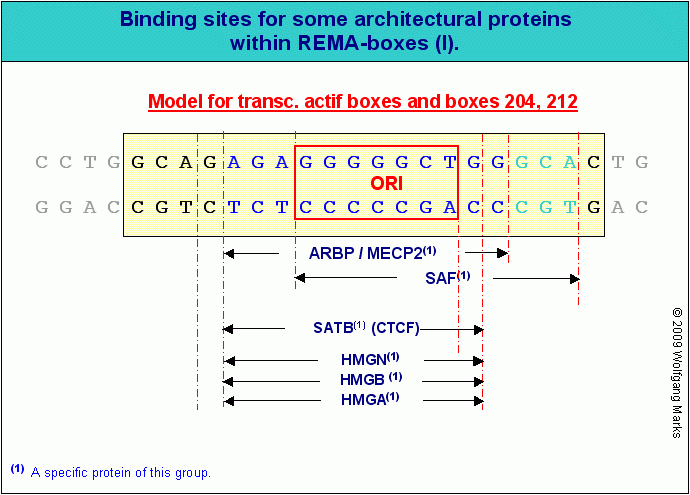
Das Attachment-Region-Binding-Protein ARBP (syn.:MeCP2).
Auch das Protein ARBP174 (Attachment Region Binding Protein – aus gallus gallus) gehört zur Gruppe der an der Chromatin-Organisation beteiligten Proteine. Ein aus 125 Aminosäureresten bestehendes Teilstück dieses Proteins stimmt zu 96,8% mit einem entsprechenden Teilstück des humanen Proteins MeCP2 überein175, das zusammen mit MBD1, MBD2, MBD3 und MBD4 zu einer Familie von Proteinen gehört, die über eine sogenannte Methyl-CpG-Binding Domain (MBD) verfügen und deshalb – mit Ausnahme von MBD4 – spezifisch an methylierte DNA binden können. MeCP2 wird als transkriptioneller Repressor apostrophiert – ausser der erwähnten an methylierte DNA bindenden Domäne enthält das Protein zwei weitere weniger gut charakterisierte Domänen: eine zentrale transkriptions-regulierende und eine C-terminale, deren Funktion noch unbekannt ist. ENSEMBLE listet für das Protein MeCP2176 fünf Transkripte auf. Nach meinen Berechnungen müssten es allerdings 6 sein – und damit ebenso viele wie es Exons haben müsste. Für die die anderen Proteine der Gruppe sind eine grosse Zahl von Transkripten und daraus abgeleiteten Proteinen dokumentiert, die ich hier nicht alle aufgezählt habe, da es mir um das Prinzip und nicht um Vollständigkeit ging (was bei vermutlich 52 mit dem processing/splicing verknüpften Proteinen in dieser Gruppe auch nicht einfach werden dürfte).
|
|
|
|
|
Die Vermutung, dass MeCP2 durch Bindung an methylierte Promotoren und methylierte CpG-Inseln spezifisch die Transkription von Genen unterdrückt, hat sich in letzter Zeit als nicht zutreffend erwiesen: durch large-scale-mapping von neuronalen MeCP2-Bindestellen in einem ca. 26,3 Mb grossen array von imprinteten und nichtimprinteten Genloci konnten Yasui et al. nachweisen177, dass 59% der MeCP2-Bindestellen ausserhalb von Genen liegen und nur 6% in CpG-Inseln. Zudem zeigte eine gemomweite integrierte Promotoranalyse der Zusammenhänge zwischen der Bindung von MeCP2, der CpG-Methylierung und der Genexpression, dass 63% der Promotoren, die MeCP2 gebunden hatten, aktiv exprimiert wurden – nur 6% aller Promotoren waren stark methyliert. Yasui et al. schliessen daraus, dass die Hauptfunktion von MeCP2 nicht das Silencing von Genen durch Bindung an methylierte Promotoren sein kann.
Auch Georgel, Horowitz-Scherer et al. kommen in ihrer Arbeit178 zu dem Schluss, dass die Silencing-Eigenschaften von MeCP2 unabhängig von DNA-Modifikationen wie zum Beispiel Methylierung sind und vermuten, dass die von ihnen beobachtete kondensierende oder kompaktierende Wirkung auf Chromatin nicht von der MDB-Domäne, sondern von einer anderen Region des Proteins bewirkt wird.
Nikitina, Shi et al.179 lokalisieren die Domäne, die für die methylierungs-unabhängige Bindung verantwortlich ist, innerhalb der ersten 294 Aminosäurereste und vermuten, das die Reste 295 bis 486 mehrere funktionelle und essentielle Domänen enthalten, die an Chromatin-Interaktionen beteiligt sind. Sie beobachteten zwei verschiedene Formen von Chromatin-Kompaktierung: eine beruhte auf der Bildung von Nukleosomen-Clustern, die andere auf der Formierung von DNA-MeCP2-DNA-Komplexen. Horike, Cai et al. schließlich konnten anhand des Dlx5-Dlx6-Locus zeigen180, dass ARBP/MeCP2 an der Formierung einer „stillen“, inaktiven Chromatin-Schleife beteiligt ist, indem es mit weit entfernten Sequenzen Kontakt aufnimmt. Diese Schleifenbildung konnte im Gehirn von MeCP2-null-Mäusen nicht beobachtet werden, ist nach Meinung von Horike et al. also spezifisch mit der Präsenz des Proteins verknüpft.
Wahrscheinlich haben das avine ARBP und das humane MeCP2 analoge Funktionen in der jeweiligen Zelle. ARBP hat, wie Weitzel et al. geschrieben haben, eine hohe Affinität zu SMARs, die auf die oben angesprochene Domäne aus 125 Aminosäureresten in der N-terminalen Region des Proteins zurückgeführt wird. ARBP bindet an Lysozym SMARs, aber auch an repetitive Sequenzen in der DNA des Huhns und an die Satelliten-DNA der Maus.181 In dieser Satelliten-DNA konnten zwei Bindestellen charakterisiert werden, deren Sequenz mit der Consensus–Sequenz der Lysozym-SMAR des Huhns (5'-GGTGT-3') korreliert war. Weitzel et al. vermuten daher, dass ARBP/MeCP2 ein multifunktionales Protein ist, das sowohl eine Rolle spielt bei der Organisation der DNA in Schleifen/loops als auch bei der Ausbildung von pericentromerem Heterochromatin und bei der DNA-Methylierung.
ARBP/MeCP2 scheint demnach ein vielseitiges Protein zu sein, das zumindest zwei verschiedene Funktionen ausübt. Die in diesem Zusammenhang interessierende ist die Fähigkeit von ARBP/MeCP2, zur Ausbildung von Chromatin-Schleifen beizutragen. Eine solche – zunächst noch inaktivierte - Chromatin-Schleife bildet sich zum Beispiel beim Entpacken des kondensierten Chromatins nach der Zellteilung zwischen den SMARs, die eine Subdomäne begrenzen (Abb.). Diese ARBP/MeCP2 vermittelte Bindung der SMARs an die Kernmatrix ist allerdings nicht die erste Stufe eines aktiv initiierten Stillegungs-Prozesses, sondern eine Stufe auf dem Weg zur Aktivierung einer Subdomäne, die von SMARs der Klasse III begrenzt wird.
|
|
|
|
|
ARBP-Proteine sind massgeblich an der Bildung der DNA-Schleifen beteiligt, die den ersten Schritt auf dem Weg zur Transkriptions-Aktivierung darstellen. Sie binden neben Proteinen der SATB-/HMGA-, HMGN- und SAF-Familie an spezifische SMARS der Klasse III, die eine Chromatin-Domäne in Subdomänen einteilen.
|
|
|
ARBP/MeCP2 und die anderen Proteine der Familie, von mir in Zukunft unter dem Begriff ARBP zusammengefasst – sind also entscheidend – und das werde ich im Kapitel Vom Chromomer zum Transkriptosom zeigen - an der Aktivierung von Subdomänen, von hnRNAs und am processing/splicing dieser hnRNAs innerhalb einer dekondensierten, aktiven Chromatin-Domäne beteiligt.
Da die meisten Architekturproteine – wenn nicht alle – in jeweils chemisch modifizierter Form sowohl an der Dekondensation als auch an der Kompaktierung der Chromatins zum Chromosom beteiligt sind, ist die ARBP/MeCP2-induzierte Schleifenbildung wahrscheinlich aber auch mit der mitotischen Kompaktierung, der mitotischen Kondensation des Chromatins und damit der Stillegung einer Domäne oder Subdomäne verbunden. Dieser Prozess läuft allerdings in der prämitotischen Phase ab. Die Aktivierung einer Subdomäne dagegen ist auf die postmitotische Phase nach der Zellteilung fokussiert.
Bei dieser Gelegenheit möchte ich daran erinnern, dass REMAKEs von Chromatin-Domänen abhängig vom Zellzyklus sowohl mitotische domänen-korrelierte Funktionen als auch Funktionen ausüben können, die mit der Inaktivierung oder Aktivierung „ihrer“ Subdomäne verknüpft sind. Der REMAKE R3 zum Beispiel hat - wie zuvor ausführlich erläutert - sowohl Funktionen im Zusammenhang mit der strukturellen Organisation der Domäne 3, als auch der Subdomäne 3.1, wenn der plus-Strang der sense-Strang ist. Analog gilt das natürlich auch für den REMAKE R4.
Wenn das Protein MeCP2-001182 zum Beispiel an seine spezifische REMA-Box 248 in einem REMAKE bindet, dann setzt es damit – so meine begründete Vermutung – die Domänen-korrelierten Funktionen dieser REMA-Box und des REMAKEs ausser Kraft, indem es das Andocken eines spezifischen SATB-248 und HMGA-248-Proteins und damit die Bildung eines Chromomers verhindert, die mit der Bindung dieser beiden Proteine verknüpft ist. Gleichzeitig rekrutiert ARBP/MECP2 das Protein SAF-248, das für die Aktivierung der Subdomäne zuständig ist. So lassen sich die zum Teil widersprüchlichen Untersuchungsergebnisse meiner Voruntersucher relativ zwanglos erklären.
Proteine der ARBP/MeCP2-Gruppe binden also an SMARS vor Subdomänen und verbinden diese SMARs mit der Kernmatrix. Diese Bindung ist wahrscheinlich mit einer spezifischen Modifikation der DNA verknüpft, die aber nur in Einzelfällen (MeCP2) aus einer Methylierung oder Demethylierung besteht. Sie sind auf diese Weise vermutlich sowohl an der Aktivierung, als auch an der temporären, reversiblen Inaktivierung von Subdomänen beteiligt.
HMG-Proteine: die alte und die neue(n) Ordnung(en).
Die sogenannten High-Mobility-Group-Proteine (HMG-Proteine) befinden sich bereits seit den 80iger-Jahren im Focus der Forschung, weil man schon früh erkannt hatte, dass diese heterogene Gruppe von sehr beweglichen Proteinen offensichtlich die Eigenschaft besitzt, die Struktur und damit auch die Funktion des Chromatins zu beeinflussen. Sie werden deshalb schon früh auch als Architekturelemente des Chromatins apostrophiert. HMG-Proteine kommen in allen bis dato untersuchten Eukarioten vor und sind phylogenetisch hoch konserviert: die Aminosäuresequenzen der HMG-Proteine von Amphibien und Mensch zum Beispiel sind nahezu gleich.
Das gemeinsame Merkmal von HMG-Proteinen ist ihre Fähigkeit, sich mit großer Geschwindigkeit durch den Zellkern zu bewegen.183 Alle HMG-Proteine weisen darüberhinaus weitere physikalische und chemische Gemeinsamkeiten auf – ihre molekulare Masse ist kleiner als 30 kD und sie weisen alle einen hohen Anteil an geladenen Aminosäuren auf (Johns, 1982).
Sprach man früher von HMG-14/17, HMG–1/2 und HMG-I/Y-Proteinen, teilt man die Proteine zur Zeit nach der sie jeweils kennzeichnenden funktionellen Domäne in die folgenden drei Gruppen ein:
|
|
Neue Bezeichnung
|
|
HMG-I/Y
|
HMGA
|
|
HMG-1/2
|
HMGB
|
|
HMG-14/17
|
HMGN
|
|
|
|
|
|
In den einzelnen Gruppen werden die Proteine zur Zeit in der Reihenfolge der Entdeckung numeriert, was zumindest solange eine vernünftige Lösung ist, wie sie nicht durch eine bessere ersetzt werden kann. Für eine solche bessere Lösung halte ich eine Nomenklatur, die auf der Verknüpfung der Proteine mit Nukleosomengrössen und Formatierungshormonen oder wie im Fall der HMGB-Familie auf der Korrelation mit Formatierungs- und sekundären Transkriptions/Processing-Hormonen basiert.
Charakteristisch für die HMGA-Proteine soll der sogenannte AT-Hook sein, für HMGB-Proteine soll die sogenannte HMG-Box spezifisch sein – HMGN-Proteine schliesslich sind durch eine Nukleosomale Bindungsdomäne gekennzeichnet.
Die HMGA-Protein-Familie.
Die HMGA-Familie besteht nach meinen Berechnungen aus insgesamt 19 Proteinen, die sich transkriptionsaktiven Nukleosomengrössen zuordnen lassen. Aktuell sind von der HMGA-Familie drei Mitglieder bekannt, die ich mittels IMPACD bestimmten Nukleosomengrössen und damit Formatierungshormonen zugeordnet habe.184 Die HMGA2-Transkriptvariante (NP_003475) – von mir „HMGA2b“ genannt - ist zwar noch nicht als Mitglied der HMGA-Familie verifiziert – ich habe sie dennoch mit dem Hormon Methionin-Enkephalin und der Nukleosomengrösse 252 verknüpft.
|
|
|
|
HMGA-Family:
Proteins: 19
Expressed from: day 5
Correlated Group of Hormones: Formatting-Hormones 1-19
Organisation of Hormonal System: 2-steps; 3-steps
|
|
|
|
Actual Name
|
Gene-Locus
|
Formatting-Hormone
|
NG
|
|
|
HMGA1a/ HMG-I
|
6p21
|
CRH
|
236
|
|
|
HMGA1b/ HMG-Y
|
6p21
|
Gn-RH
|
240
|
|
|
HMGA2a/HMG-C
|
12q15
|
MSH-RH
|
244
|
|
|
HMGA2b/NP_003475
|
12q15
|
Methionin-Enkephalin
|
252
|
|
HMGA-Proteine sollen bevorzugt an die kleine Furche der B-DNA binden und dies vor allem in AT-reichen Abschnitten185. Die Bindung an die DNA soll von drei AT-Hook-DNA-Bindungsmotiven vermittelt werden, wie diese Bindung etabliert wird, ist aber nicht mit Bestimmtheit gewußt. Entscheidender als die Bindungssequenz der Ziel-DNA soll die dreidimensionale Struktur der DNA sein: anscheinend binden HMGA-Proteine bevorzugt an „verdrehte“ oder „geknickte“ DNA.
Durch Bindung von HMGA-Proteinen kann lineare DNA verbogen werden – vice versa können Verbiegungen in verbogener oder geknickter DNA durch HMGA-Proteine auch wieder entfernt werden. Ausserdem kann durch Bindung von HMGA-Proteinen DNA partiell entwunden oder zu Schleifen geformt werden. Dieses Phänomen, das uns später noch interessieren wird, wurde m.W. zuerst von Lehn et al. (1988), später auch von Falvo et al. ( 1995),Chase et al. (1999), Bagga et al. und Liu et al. (jeweils 2000) beschrieben. Für die Konformationsänderung der DNA wurden unterschiedliche Mechanismen als mögliche Ursachen angeführt: in der Diskussion ist sowohl das Andocken der drei AT-Hooks eines einzelnen HMGA-Moleküls an weit voneinander entfernte Bereiche der Ziel-DNA, als auch die koordinierte Bindung mehrerer Moleküle an bestimmte Bereiche der DNA und ein darauf folgendes nicht kovalentes cross-linking (Reeves, 2001).
HMGA-Proteine werden nach ihrer Translation im Zytoplasma im Zellkern vielfach chemisch modifiziert: Phosphorylierung, Azetylierung, Methylierung und Poly-ADP-Ribosylierung ist beschrieben worden (Zusammenfassung 2001 von Reeves und Beckerbauer). Phosphorylierung und Azetylierung scheinen in vitro die Bindungseigenschaften und die biologische Aktivität von HMGA-Proteinen zu beeinflussen (Nissen et al. (1991); Reeves et al. (1991). Die Phosphorylierung von HMGA-Proteinen scheint abhängig vom Zellzyklus zu sein und wird sowohl von endogenen zellulären Signalen kontrolliert (Detivaud et al. (1999), als auch von Signalereignissen an oder in der Zellmembran beeinflusst (Wang et al., 1995; Banks et al., 2000; Xiao et al., 2000.
Disney et al. (1989) und Reeves (1992) sowie Saitoh und Laemmli (1994) haben beschrieben, dass HMGA-Proteine aktiv an der dynamischen Änderung der Chromatinstruktur während der Chromosomenkondensation zum Zwecke der Zellteilung beteiligt sind. HMGA-Proteine haben aber auch einen direkten Einfluss auf die Genexpression: die durch HMGA induzierte Elimination von DNA-Verbiegungen steht in direktem Zusammenhang mit der Rekrutierung von Transkriptionsfaktoren (Thanos und Maniatis, 1995) und remodeling-Maschinen, so zum Beispiel des SWI/SNF-Komplexes (Agresti und Bianchi, 2003).
Die bis jetzt bekannten HMGA-Proteine werden überwiegend in nicht ausdifferenzierten Zellen oder Embryonalzellen exprimiert. In ausdifferenzierten Zellen ist nur wenig HMGA nachweisbar (Bustin und Reeves, 1996); Chiapetta et al. 1996). Eine Überexpression von HMGA-Proteinen ist ebenso mit malignen Prozessen verbunden wie das Fehlen des Proteins. Bei einer HMGA2-knock-out-Maus führt das Fehlen des Proteins zu Zwergen-wachstum – bei der Überexpression von HMGA2 werden vermehrt Fettzellen gebildet, was nach Meinung von Anand und Chada (2000) darauf hinweisen könnte, dass HMGA2 eine Rolle bei der Adipogenese spielt.
Schließlich sind HMGA-Proteine in vielen malignen Tumoren überexprimiert (u.a. bei Brust-, Prostata-, Colon-, Magen-, Haut – und Lungenkrebs (Reeves und Beckerbauer, 2001), aber auch in benignen Bindegewebstumoren ist eine abnorme Produktion von HMGA(2) – Proteinen zu beobachten (Battista et al., 1999; Arlotta et al., 2000).
Die HMGB-Protein-Familie.
Zur HMGB-Gruppe werden zur Zeit drei Proteine gezählt: das HMGB1 (früher HMG-1), das HMGB2 (früher HMG-2) und schließlich HMGB3 (früher HMG2a). Auch für diese Protein-Gruppe postuliere ich eine bestimmte Anzahl von Mitgliedern: da auch HMGB – wie ich noch zeigen werde – ab einer bestimmten Phase der Ontogenese mit der Aktivierung von Transkriptionsschleifen innerhalb von Subdomänen verbunden ist, sollte diese Familie aus insgesamt 31 verschiedenen Proteinen bestehen, die allesamt mit dem processing, dem Spleissen von Primärtranskripten verknüpft sind und durch sekundäre Transkriptionshormone aktiviert werden.
|
|
|
|
|
HMGB-Family:
Proteins: 52
Expressed from: day 110
Correl. Group of Hormones: Second. Transcriptional-Hormones (FH12-19)
Organisation of Hormonal System: 3-steps
|
|
|
|
Actual Name
|
Gene-Locus
|
Prim. Transcr. Hormone
|
Sec. Transcr. Hormone
|
|
|
HMGB3/HMG2A
|
Xq28
|
Dopamin
|
PGE2
|
|
|
HMGB2/HMG2
|
4q31
|
FSH
|
?
|
|
|
HMGB1/HMG1
|
13q12
|
GABA
|
ß-Lipotropin
|
|
Im Vergleich zu den anderen Gruppen von HMG-Proteinen besitzen die bis jetzt bekannten HMGB-Moleküle eine größere Masse (ca. 25 kD) – sie sollen die am häufigsten im Zellkern vertretenen HMG-Proteine186 sein (ein Molekül auf ca. 10-15 Nukleosomen) und kommen in allen bis jetzt untersuchten eukariotischen Zellen vor. Die bis jetzt bekannten HMGB-Proteine werden zwar auf unterschiedlichen Genen kodiert, sind sich aber trotzdem sehr ähnlich: ca. 82% der Aminosäuren von HMGB1 und HMGB2 zum Beispiel sind identisch. Da die Proteine zudem hochkonserviert187 sind, wird vermutet, dass ihnen eine zentrale Funktion im Säugergenom zukommt.
Ihren Namen verdanken die HMGB-Proteine zwei charakteristischen Domänen (Boxen): einer N-terminalen sogenannten A-Domäne und einer zentral gelegenen B-Domäne, ergänzt durch einen negativ geladenen C-terminalen Bereich aus 20 bis 30 aufeinanderfolgenden Aspartat- und Glutamatresten. Jede der beiden Boxen besteht aus etwa 80 bis 90 stark basischen Aminosäuren, die eine gedrehte L-förmige, homolog gefaltete Domäne aus drei α-Helices bilden. Die Boxen binden mit nur geringer Spezifität an die kleine Furche von B-DNA, wobei die A-Box eine höhere Affinität für ungewöhnliche DNA-Formen, so zum Beispiel für kreuzförmige, gebogene und supergecoilte DNA aufweist als die B-Box. Die Bindung an relaxierte Plasmid-DNA führt in vitro zu einer Einführung von Supercoils. (Zusammenfassung in Thomas und Travers, 2001).
Die DNA-Bindung erfolgt ausschließlich an der kleinen Rinne der DNA durch interkalierende, hydrophobe Aminosäuren. Dies führt zu einer teilweisen Entwindung der DNA und dadurch zu einer Erweiterung der kleinen Rinne. Allerdings sind die Interaktionen von HMGB-Proteinen sowohl mit anderen Proteinen als auch mit DNA immer transient und nur von sehr kurzer Dauer.
HMGB-Proteine können durch Transkriptionsfaktoren rekrutiert werden und führen in den relevanten Bereichen zu DNA-Strukturveränderungen, welche offenbar die Transkription erleichtern. Nach Initiation der Transkription verlassen sie diese Stelle(n) wieder. Deshalb werden HMGB-Proteine auch als „Architektur-Transkriptionsfaktoren“, als „Chromatin-Chaperone“ oder auf Grund ihrer hohen Mobilität im Zellkern auch als „an architect for hire“ bezeichnet.
HMGB-Proteine sollen wie auch die HMGA-Proteine eine Rolle bei der Ausbildung von Enhanceosomen spielen, allerdings sind bis jetzt nur wenige „B-Enhanceosomen“ bekannt, was dadurch erklärt wird, dass ihre Beobachtung aufgrund der transienten Bindung schwierig sei (nach Agresti und Bianchi, 2003).
HMGB-Proteinen werden zahlreiche Funktionen zugeschrieben – ihre Haupfunktion soll aber sein, durch Bindung an die DNA diese in eine bestimmte Konformation zu zwingen, indem sie die DNA verbiegen. Anscheinend binden HMGB-Proteine bevorzugt an DNA, deren Konformation bereits verändert wurde: so zum Beispiel an „4-way-junctions“, an DNA mit eingebauten Nukleotid-Analogen (Krynetsky et al., 2003), an durch UV-Strahlung beschädigte (Pasheva et al., 1998) oder durch Cisplatin modifizierte DNA (Ohndorf et al., 1999).
HMGB-Moleküle sind außerordentlich mobil: sie können in nur 1,5 Sekunden den gesamten Zellkern durchqueren. Daraus hat man geschlossen, dass diese Proteine nicht aktiv zu ihren Ziel-Sequenzen in der DNA transportiert werden, sondern nach dem „try-and-error“-Prinzip mehr oder weniger zufällig durch Diffusion zu diesen DNA-Abschnitten gelangen (zusammengefasst in Agresti und Bianchi, 2003).
HMGB-Proteine können die Genexpression beeinflussen. In vitro wurde die sequenz-spezifische Bindung von Progesteron-Rezeptoren an ihre response-Elemente auf der DNA durch die Zugabe von HMGB1-Proteinen ebenso verstärkt (Onate et al., 1994) wie die eines Östrogen-Rezeptors in einem vergleichbaren Versuch (Verrier et al., 1997). Auch mit chromatin-remodeling werden HMGB-Proteine in Verbindung gebracht: in Drosophila unterstützen sie offensichtlich die Bindung des ACF-remodeling-Komplexes an die DNA.
HMGB-Proteine sollen aber auch die RNA-Polymerase II – abhängige Transkription unterdrücken können, indem sie mit dem Tatabox-Binding-Protein (TBP) einen Komplex bilden und durch kompetitive Hemmung der TFIIB-Interaktion mit TBP die Bildung des Prä-Initiations-Komplexes (PIC) unterbinden (Ge und Roeder, 1994). Sollte diese Beobachtung zutreffen, dann würden für HMGB wahrscheinlich die gleichen Anmerkungen zutreffen, die ich weiter oben für die Proteinfamilie ARBP/MeCP2 getroffen habe:
In vitro konnte für HMGB1 nachgewiesen werden, dass durch die DNA-biegende Eigenschaft des Proteins das „Nukleosomen-Sliding“ durch den ACF/CHRAC-remodeling-Komplex erleichtert wird (Bonaldi et al., 2002).
Die HMGN-Protein-Familie.
Die folgende Tabelle fasst sowohl die von mir mittels IMPACD® identifizierten188 als auch die bereits bekannten HMGN-Genloci zusammen und bringt sie in einen systematischen Zusammenhang mit dem Nukleosomengr√∂ssen- und dem Formatierungshormon-System.
|
|
|
|
HMGN-Family:
Proteins: 19
Expressed from: day 5
Correlated Group of Hormones: Formatting-Hormones 1-19
Organis. of Hormonal System: 2-steps; 3-steps
|
|
Nr.
|
Syst. Name
|
Actual Name
|
Gene-Locus
|
Formatting
Hormone
|
FH/NG
|
|
1
|
HMGN-176
|
-
|
16p
|
PGF2α
|
176
|
|
2
|
HMGN-180
|
-
|
17p
|
PGB2
|
180
|
|
3
|
HMGN-184
|
-
|
17p
|
HCG
|
184
|
|
4
|
HMGN-188
|
-
|
14q
|
PGF2ß
|
188
|
|
5
|
HMGN-192
|
-
|
15p
|
HPL
|
192
|
|
6
|
HMGN-196
|
-
|
17q
|
Estriol
|
196
|
|
7
|
HMGN-200
|
-
|
16q
|
Progesteron
|
200
|
|
8
|
HMGN-216
|
-
|
3p
|
Thymosin-ß10
|
216
|
|
9
|
HMGN-220
|
-
|
13p
|
Thymosin-ß15
|
220
|
|
10
|
HMGN-224
|
HMGN1-(HMG14)
|
21q22*
|
Thymopoetin
|
224
|
|
11
|
HMGN-228
|
-
|
18p
|
Thymosterin
|
228
|
|
12
|
HMGN-232
|
HMGN3a
|
6q14.1
|
TRH
|
232
|
|
13
|
HMGN-236
|
-
|
16q
|
CRH
|
236
|
|
14
|
HMGN-240
|
-
|
15q
|
Gn-RH
|
240
|
|
15
|
HMGN-244
|
HMGN4
|
6p21.3
|
MSH-RH
|
244
|
|
16
|
HMGN-248
|
HMGN2-(HMG17)
|
1p36.1
|
GH-RH
|
248
|
|
17
|
HMGN-252
|
HMGN3b
|
6q14.1
|
Methionin-
Enkephalin
|
252
|
|
18
|
HMGN-256
|
NSBP1(NBP-45)**
|
Xq13.3
|
Leuzin-
Enkephalin
|
256
|
|
19
|
HMGN-260
|
-
|
14p
|
ß-Endorphin
|
260
|
|
* red =known loci;
blue=postulated/identified by author.
From all genes exist copies on other loci.
** NSBP1 is the human analogue to the murine protein NBP-45.
|
|
HMGN-Proteine wurden bereits Anfang der 80er-Jahre aus Säugerzellen isoliert und als chromosomale Nicht-Histon-Proteine klassifiziert (Johns, 1982). Später fand man diese Proteine in allen Zellen der bisher untersuchten Säuger und Vertebraten. Bisher hat man 5 Proteine dieser Gruppe entdeckt (sechs, wenn man NBP-45/NSBP1 – das ich auch zu den HMGN-Proteinen zähle – mitrechnet). Shirakawa et al., die das Protein NBP-45 identifiziert und charakterisiert haben189 , vermuten, dass die sogenannte NBD, die nukleosomale Bindungs-Domäne, ein signifikantes gemeinsames Merkmal von Proteinen ist, welche die Fähigkeit haben, die Struktur der DNA zu so verändern, dass Transkription und Replikation ermöglicht werden.
HMGN-Proteine verdanken ihren Namen der Tatsache, dass sie eine höhere Affinität zu Nukleosomen aufweisen als zu DNA: HMGN1 und HMGN2 binden in vitro mit hoher Affinität als Homodimere an (durchschnittlich 6 aufeinanderfolgende) Nukleosomen und bilden so Chromatinbereiche, in denen entweder nur HMGN1 oder HMGN2 (früher HMG14 bzw. HMG17) zu finden ist. Diese Chromatinabschnitte sind zu größeren Domänen zusammengefasst, in denen ebenfalls nur HMGN1 oder HMGN2 zu finden ist. Die Proteine sind also nicht gleichmässig an das Chromatin gebunden, sondern in unterschiedlichen Foci innerhalb des Zellkerns lokalisiert. Experimentelle Verdrängung von HMGN1 und /oder HMGN2 führte zu einer Verringerung der Transkriptionsrate, in diesem Fall reichern sich die Proteine in den Interchromatin-Granula an. Bei vollständiger Hemmung der Transkription ist HMGN2 fast ausschließlich in den Interchromatin-Granula konzentriert. Zumindest HMGN2 zeigt also eine von der Transkriptionsaktivität abhängige dynamische Umverteilung (R.Hock, M. Bustin 1997).
Hock und Bustin konnten belegen, dass HMGN-Proteine während der Mitose nicht mit den Chromosomen assoziiert, also ein Bestandteil des Interphase-Chromatins sind. Dass HMGN1 und HMGN2 als relativ kleine Proteine nicht durch Diffusion in den Zellkern gelangen, sondern energieabhängig (Importin) in den Zellkern transportiert werden, war überraschend und zeigt ebenfalls, dass diese Proteine eine wichtige Funktion im Zellkern haben müssen.
Während der Mitose liegen HMGN1 und HMGN2 in einer phosphorylierten Form vor: neuere Ergebnisse lassen vermuten, dass die dynamische Umverteilung von HMGN-Proteinen - die Ablösung vom kondensierten Chromatin in der Mitose, der Kernimport und vielleicht auch die Akkumulation in den IC-Granula) – auf einer zellzyklusabhängigen Phosphorylierung der nukleosomalen Bindungsdomäne dieser Proteine beruhen. Wenn die beiden Proteine an ihrer nukleosomalen Bindungsstelle phosphoryliert werden, könnte diese Modifikation die Affinität der Proteine für Nukleosomen vermindern – im Umkehrschluss die Dephosphorylierung der Proteine ihre Affinität zu Nukleosomen wiederherstellen. Robert Hock konnte am Beispiel des südafrikanischen Krallenfrosches (Xenopus laevis) zeigen, dass HMGN-Proteine in der Frühentwicklung des Embryos, die ausschließlich von maternalen Faktoren gesteuert wird, fehlen – erst mit Einsetzen der (differentiellen) Genexpression lassen sich HMGN1 und HMGN2 wieder im Embryo nachweisen.
HMGN-Proteine scheinen also ein integraler Bestandteil des Chromatins zu sein – sie sind permanent mit spezifischen Chromatinabschnitten assoziiert. Diese Assoziation ist abhängig von der Transkriptionsaktivität der Zelle und wird durch chemische Modifikation (Phosphorylierung/Dephosphorylierung) der nukleosomalen Bindungsdomäne bewirkt.
Lim et al. (2002) postulieren, dass ein Großteil der HMGN-Proteine in makromolekularen Komplexen organisiert sind: in HeLa-Zellen fanden sie sowohl HMGN1 als auch HMGN2 in größeren metastabilen Komplexen, deren andere Komponenten aber nicht identifiziert werden konnten. Wurde die Transkription in den Zellen inhibiert, erhöhte sich die Anzahl der freien, ungebundenen HMGN-Moleküle und vice versa. Die Inkorporation in makromolekulare Komplexe ist also offensichtlich mit der metabolischen Aktivität der Zelle korreliert.
Lim et al. konnten auch nachweisen, dass die Bindungsaffinität zwischen komplexgebundenen HMGN-Proteinen und Nukleosomencores größer ist als die zwischen ungebundenen HMGN-Proteinen und Corepartikeln.
Spezifische Messverfahren (Fluoreszenzmarkierung) ergaben für die Geschwindigkeit (Diffusionskonstante), mit der sich HMGN1- und HMGN2-Proteine durch den Zellkern bewegen, Werte von 0,5μm2/s – das würde bedeuten, dass sie in etwa 5 Sekunden den gesamten Zellkern durchqueren könnten. Nicht zuletzt aufgrund dieser Berechnungen vermutet man, dass circa 90% aller HMGN-Proteine im Zellkern transient an Nukleosomen gebunden vorliegen müssen.
|
|
|
170„Funktionsanalysen nicht-kodierender genomischer DNA-Bereiche unter Berücksichtigung biomathematischer Modelle“; Sandra Götze, Dissertation an der Gemeinsamen Naturwissenschaft-lichen Fakultät der Technischen Universität Carolo-Wilhelmina zu Braunschweig.
171„Funktionelle Rolle von HMGN Proteinen während der Embryonalentwicklung von Xenopus laevis“, Dissertation zur Erlangung des naturwissenschaftlichen Doktorgrades der Bayerischen Julius-Maximilians-Universität Würzburg, vorgelegt von Ulrich Körner, Würzburg 2004.
http://deposit.ddb.de/cgi-bin/dokserv?idn=972677194&dok_var=d1&dok_ext=pdf&filename=972677194.pdf
172Beide Beobachtungen können meines Erachtens auf Grund der Funktion des Proteins nur für bestimmte Proteine der Gruppe zutreffen.
173Viele SATB-Proteine – wenn nicht alle – sind identisch oder teilidentisch mit Proteinen, die als Kofaktoren bzw. Mediatoren bezeichnet werden und als solche im Transkriptionskomplex mit dem generellen Transkriptionsfaktor TFIID und anderen TF oder der RNAPII kooperieren. Diese Feststellung gilt auch für andere Architekturproteine, die ich in diesem Teil III vorstellen und besprechen werde. MED26 (mediator complex subunit 26) entspräche in dem von mir postulierten System der SATB-Proteine dem SATB-244-MSH.
174De jure hätte ich diese Protein-Familie nach dem humanen Protein MeCP2 benennen müssen – da aber der Terminus ARBP die Funktion zutreffender beschreibt, habe ich mich für diesen Begriff entschieden.
175Chicken MAR-binding protein ARBP is homologous to rat methyl-CpG-binding protein MeCP2. Weitzel JM, Buhrmester H, Strätling WH.; Mol Cell Biol. 1997 Sep;17(9):5656-66.
176http://www.ensembl.org/Homo_sapiens/Transcript/Summary?db=core;g=ENSG00000169057;r=X:152940218-153016406;t=ENST00000369964
177Integrated epigenomic analyses of neuronal MeCP2 reveal a role for long-range interaction with active genes; Yasui DH, Peddada S, Bieda MC, Vallero RO, Hogart A, Nagarajan RP, Thatcher KN, Farnham PJ, Lasalle JM; Proc Natl Acad Sci U S A. 2007 Dec 4;104(49):19416-21;
178Chromatin compaction by human MeCP2. Assembly of novel secondary chromatin structures in the absence of DNA methylation; Georgel PT, Horowitz-Scherer RA, Adkins N, Woodcock CL, Wade PA, Hansen JC; J Biol Chem. 2003 Aug 22;278(34):32181-8;
179Multiple modes of interaction between the methylated DNA binding protein MeCP2 and chromatin;
Nikitina T, Shi X, Ghosh RP, Horowitz-Scherer RA, Hansen JC, Woodcock CL; Mol Cell Biol. 2007 Feb;27(3):864-77;
180Loss of silent-chromatin looping and impaired imprinting of DLX5 in Rett syndrome; Horike S, Cai S, Miyano M, Cheng JF, Kohwi-Shigematsu T; Nat Genet. 2005 Jan;37(1):31-40
181Nach meinen Analysen bindet ARBP auch an SMARs der Klasse II, welche die Transkription von ALU-Genen und REMA-Genen regulieren. Beide Gensysteme basieren auf repetitiven Sequenzen.
182Siehe √úbersicht ARBP-Familie
183Allerdings verdanken sie ihren Namen nicht dieser Eigenschaft, sondern ihrem Laufverhalten in der SDS-Gel-Elektrophorese.
184Ich werde die Tabelle zu einem späteren Zeitpunkt vervollständigen.
185Nach dem Ergebnis meiner Analysen bindet HMGA – wie bereits ausgeführt – an REMA-Boxen von REMAKEs/SMARs. Diese sind nicht immer, aber von Fall zu Fall auch AT-reich.
186Diese Ansicht teile ich nicht. Von den drei HMG-Familien sind m.E. am häufigsten im Zellkern vertreten die HMGN-Proteine.
187Bei allen bislang untersuchten Säugern fand man nur zwei Substitutionen innerhalb von 214 Aminosäuren.
188Die Genloci werde ich aus patentrechtlichen Gründen erst später bekanntgeben
189NBP-45, a Novel Nucleosomal Binding Protein with a Tissue-specific and Developmentally Regulated Expression; Hitoshi Shirakawa, David Landsman, Yuri V. Postnikov, and Michael Bustin; J Biol Chem, Vol. 275, Issue 9, 6368-6374, March 3, 2000
|
|
|

{kind=link}